Go栈内存管理
栈内存
栈区的内存由编译器自动进行分配和释放,栈区中存储着函数的参数以及局部变量,它们会随着函数的创建而创建,函数的返回而销毁。
每个goroutine都维护着一个自己的栈区,这个栈区只能自己使用不能被其他goroutine使用。栈区的初始大小是2KB.
栈内存空间、结构和初始大小经过了几个版本的更迭
- v1.0 ~ v1.1 : 最小栈内存空间为4KB;
- v1.2 : 将最小栈内存提升到了8KB;
- v1.3 : 使用连续栈替换之前版本的分段栈;
- v1.4 ~ v1.19 : 将最小栈内存降低到了2KB;
栈结构经过了分段栈到连续栈的发展过程,介绍如下。
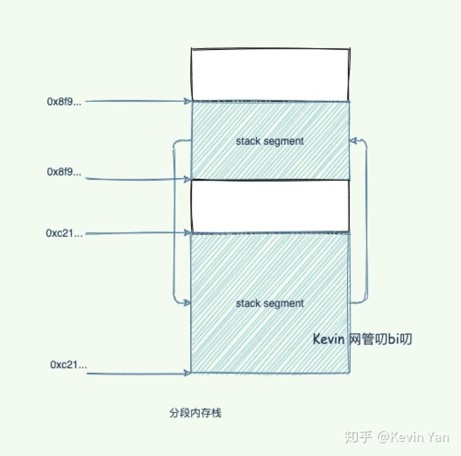
分段栈
随着goroutine调用的函数层级的深入或者局部变量需要的越来越多时,运行时会调用runtime.morestack和runtime.newstack 创建一个新的栈空间,这些栈空间是不连续的,但是当前goroutine的多个栈空间会以双向链表的形式串联起来,运行时会通过指针找到连续的栈片段。 如下图所示。
优点:
按需为当前goroutine分配内存并且及时减少内存的占用。
缺点:
如果当前goroutine的栈几乎充满,那么任意的函数调用都会触发栈的扩容,当函数返回后又会触发栈的收缩,如果在一个循环中调用函数,栈的分配和释放就会造成巨大的额外开销,这被称为热分裂问题(Hot split)。
为了解决这个问题,Go在1.2版本的时候不得不将栈的初始化内存从4KB增大到了8KB。
连续栈
连续栈可以解决分段栈中存在的两个问题,其核心原理就是每当程序的栈空间不足时,初始化一片比旧栈大两倍的新栈并将原栈中的所有值都迁移到新的栈中,新的局部变量或者函数调用就有了充足的内存空间。
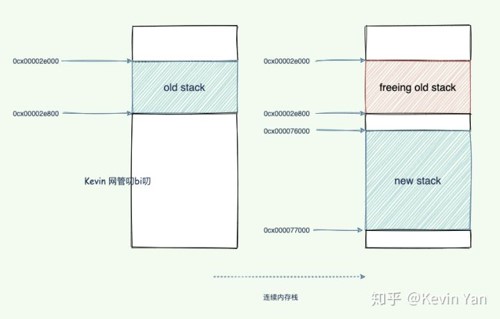
栈空间不足导致的扩容会经历以下几个步骤:
- 调用用
runtime.newstack在内存空间中分配更大的栈内存空间; - 使用
runtime.copystack将旧栈中的所有内容复制到新的栈中; - 将指向旧栈对应变量的指针重新指向新栈;
- 调用
runtime.stackfree销毁并回收旧栈的内存空间;
栈管理
Span除了用作堆内存分配外,也用于栈内存分配,只是用途不同的Span对应的mSpan状态不同。用做堆内存的mSpan状态为mSpanInUse,而用做栈内存的状态为mSpanManual。
栈空间在运行时中包含两个重要的全局变量,分别是runtime.stackpool和runtime.stackLarge,这两个变量分别表示全局的栈缓存和大栈缓存,前者可以分配小于 32KB 的内存,后者用来分配大于 32KB 的栈空间。
为提高栈内存分配效率,调度器初始化时会初始化两个用于栈分配的全局对象:stackpool 和stackLarge,介绍如下。
StackPool
stackpool面向32KB以下的栈分配,栈大小必须是2的幂,最小2KB,在Linux环境下,stackpool提供了2kB、4KB、8KB、16KB四种规格的mSpan链表。
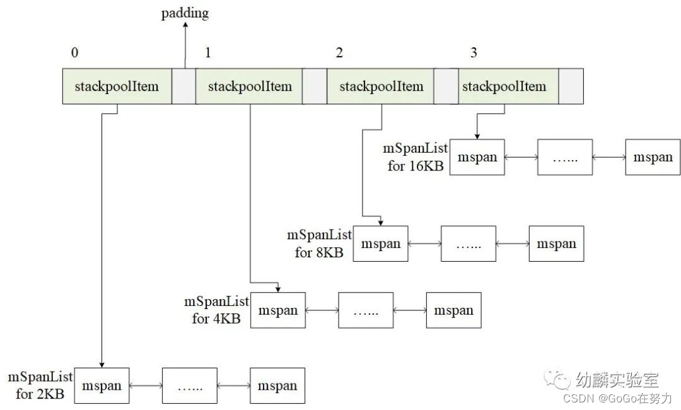
stackpool结构定义如下:
1 | // Global pool of spans that have free stacks. |
StackLarge
大于等于32KB的栈,由stackLarge来分配,这也是个mSpan链表的数组,长度为25。mSpan规格从8KB开始,之后每个链表的mSpan规格都是前一个的两倍。
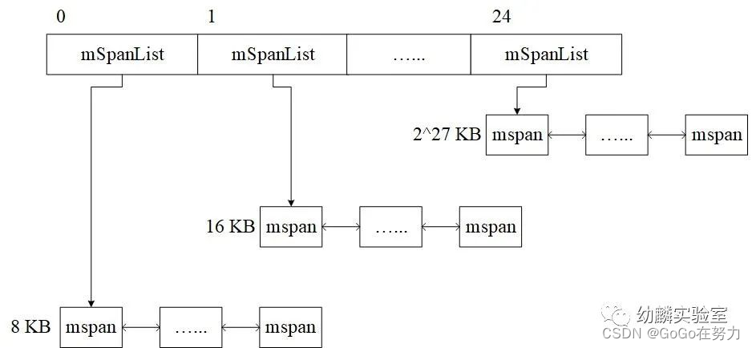
8KB和16KB这两个链表,实际上会一直是空的,留着它们是为了方便使用mSpan包含页面数的(以2为底)对数作为数组下标。
stackLarge结构定义如下:
1 | // Global pool of large stack spans. |
内存分配
如果运行时只使用全局变量来分配内存的话,势必会造成线程之间的锁竞争进而影响程序的执行效率,栈内存由于与线程关系比较密切,所以在每一个线程缓存runtime.mcache中都加入了栈缓存减少锁竞争影响。
同堆内存分配一样,每个P也有用于栈分配的本地缓存(mcache.stackcache),这相当于是stackpool的本地缓存,在mcache中的定义如下:
1 | //go:notinheap |
stackcache [_NumStackOrders]stackfreelist即为栈的本地缓存,在Linux环境下,每个P本地缓存有4(_NumStackOrders)种规格的空闲内存块链表:2KB,4KB,8KB,16KB,定义如下所示:
1 | // Number of orders that get caching. Order 0 is FixedStack |
小于32KB的栈分配:
- 对于小于32KB的栈空间,会优先使用当前P的本地缓存。
- 如果本地缓存中,对应规格的内存块链表为空,就从stackpool这里分配16KB的内存放到本地缓存(
stackcache)中,然后继续从本地缓存分配。 - 若是
stackpool中对应链表也为空,就从堆内存直接分配一个32KB的span划分成对应的内存块大小放到stackpool中。不过有些情况下,是无法使用本地缓存的,在不能使用本地缓存的情况下,就直接从stackpool分配。
大于等于32KB的栈分配:
- 计算需要的page数目,并以2为底求对数(log2page),将得到的结果作为stackLarge数组的下标,找到对应的空闲
mSpan链表。 - 若链表不为空,就拿一个过来用。如果链表为空,就直接从堆内存分配一个拥有这么多个页面的span,并把它整个用于分配栈内存;
- 例如想要分配64KB的栈,68/8是8个page,log2page=log2(8)=3
内存释放
什么时候释放栈?
- 如果协程栈没有增长过(还是2KB),就把这个协程放到有栈的空闲G队列中;
- 如果协程栈增长过,就把协程栈释放掉,再把协程放入到没有栈的空闲G队列中。而这些空闲协程的栈,也会在GC执行
markroot时被释放掉,到时候这些协程也会加入到没有栈的空闲协程队列中。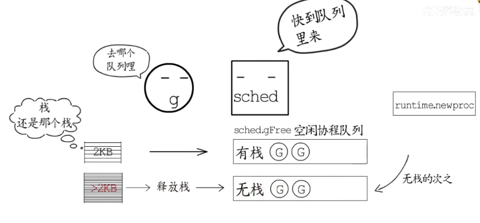
所以,常规goroutine栈的释放,一是发生在协程运行结束时,gfput会把增长过的栈释放掉,栈没有增长过的g会被放入sched.gFree.stack中;二是GC会处理sched.gFree.stack链表,把这里面所有g的栈都释放掉,然后把它们放入sched.gFree.noStack链表中。
协程栈释放时是放回当前P的本地缓存?还是放回全局栈缓存?还是直接还给堆内存?
- 其实都有可能,要视情况而定,同栈分配时一样,小于32KB和大于等于32KB的栈,在释放的时候也会区别对待。
- 小于32KB的栈,释放时会先放回到本地缓存中。如果本地缓存对应链表中栈空间总和大于32KB了,就把一部分放回
stackpool中,本地这个链表只保留16KB。如果本地缓存不可用,也会直接放回stackpool中。而且,如果发现这个mSpan中所有内存块都被释放了,就会把它归还给堆内存。 - 对于大于等于32KB的栈释放,如果当前处在GC清理阶段(
gcphase==_GCoff),就直接释放到堆内存,否则就先把它放回StackLarge这里。
栈扩容
在goroutine运行的时候栈区会按照需要增长和收缩,占用的内存最大限制的默认值在64位系统上是1GB。栈大小的初始值和上限这部分的设置都可以在Go的源码runtime/stack.go查看。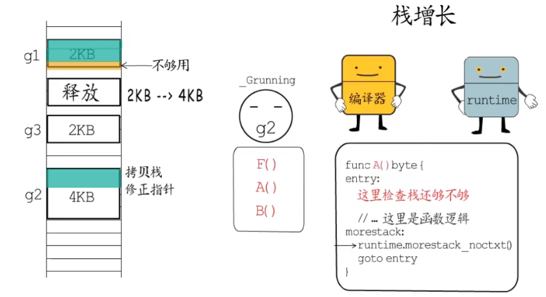
扩容流程
- 编译器会为函数调用插入运行时检查
runtime.morestack,它会在几乎所有的函数调用之前检查当前goroutine的栈内存是否充足,如果当前栈需要扩容,会调用runtime.newstack创建新的栈 。 - 旧栈的大小是通过我们上面说的保存在
goroutine中的stack信息里记录的栈区内存边界计算出来的,然后用旧栈两倍的大小创建新栈,创建前会检查是新栈的大小是否超过了单个栈的内存上限。 - 整个过程中最复杂的地方是将指向源栈中内存的指针调整为指向新的栈,这一步完成后就会释放掉旧栈的内存空间了
栈缩容
在goroutine运行的过程中,如果栈区的空间使用率不超过1/4,那么在垃圾回收的时候使用runtime.shrinkstack进行栈缩容,当然进行缩容前会执行一堆前置检查,都通过了才会进行缩容。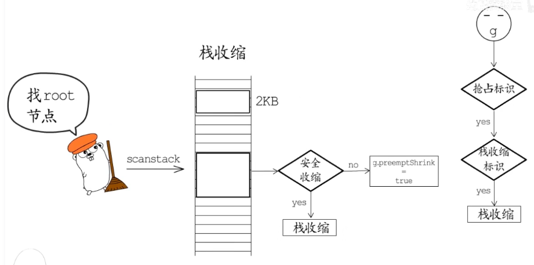
缩容流程
- 如果要触发栈的缩容,新栈的大小会是原始栈的一半,如果新栈的大小低于程序的最低限制 2KB,那么缩容的过程就会停止。
- 缩容也会调用扩容时使用的
runtime.copystack函数开辟新的栈空间,将旧栈的数据拷贝到新栈以及调整原来指针的指向。
唯一发起栈收缩的地方就是 GC。GC通过scanstack函数寻找标记root节点时,如果发现可以安全的收缩栈,就会执行栈收缩,不能马上执行时,就设置栈收缩标识(g.preemptShrink = true),等到协程检测到抢占标识(stackPreempt)。在让出CPU之前会检查这个栈收缩标识,为true的话就会先进行栈收缩,再让出CPU。
参考
https://blog.csdn.net/weixin_52690231/article/details/124476954
https://zhuanlan.zhihu.com/p/237870981

